
Jeonghwan Kim
Ph.D. Candidate, BLENDER Lab, UIUC
jk100 [AT] illinois.edu
About
Ph.D. candidate at BLENDER Lab at the University of Illinois Urbana-Champaign (UIUC), advised by Professor Heng Ji. I am also a recipient of the Capital One Ph.D. Fellowship (2026–2027).
I work on multimodal foundation models, with a focus on enabling models to perceive, ground, and reason over fine-grained visual information. My research explores how vision and language can be integrated to build richer representations that capture objects, attributes, relations, and dynamics for reliable reasoning and decision-making.
More broadly, I develop methods for visual grounding, cross-modal alignment, and knowledge integration, with the goal of making multimodal systems more accurate, interpretable, and capable of understanding the physical world.
Recently, I have been interested in extending these capabilities to visually grounded action policies for embodied AI and robotics, connecting perception, reasoning, and action in real-world environments.
Specifically, I design models that:
- Advance multimodal foundation models through fine-grained visual perception and grounding
- Align localized visual information with parametric and non-parametric knowledge
- Enable visually grounded reasoning and action for embodied agents operating in real-world environments
Research Experience
MetaRedmond, WA, USA
Research Scientist Intern May. 2026 - Present
Part-time Student Researcher May. 2025 - Oct. 2025
AmazonBellevue, WA, USA
Applied Scientist Intern May. 2024 - Aug. 2024
University of Illinois Urbana-Champaign (UIUC) Champaign, IL, USA
Graduate Research Assistant (Ph.D.) Aug. 2023 - Present
Advisor: Heng Ji
KAIST IR&NLP Lab Daejeon, Republic of Korea
Research Associate Mar. 2022 - July. 2023
Graduate Research Assistant (M.S.) Feb. 2020 - Feb. 2022
Advisor: Sung-Hyon Myaeng
Selected Publications
For more information, check out my Google Scholar.
* indicates equal contribution.
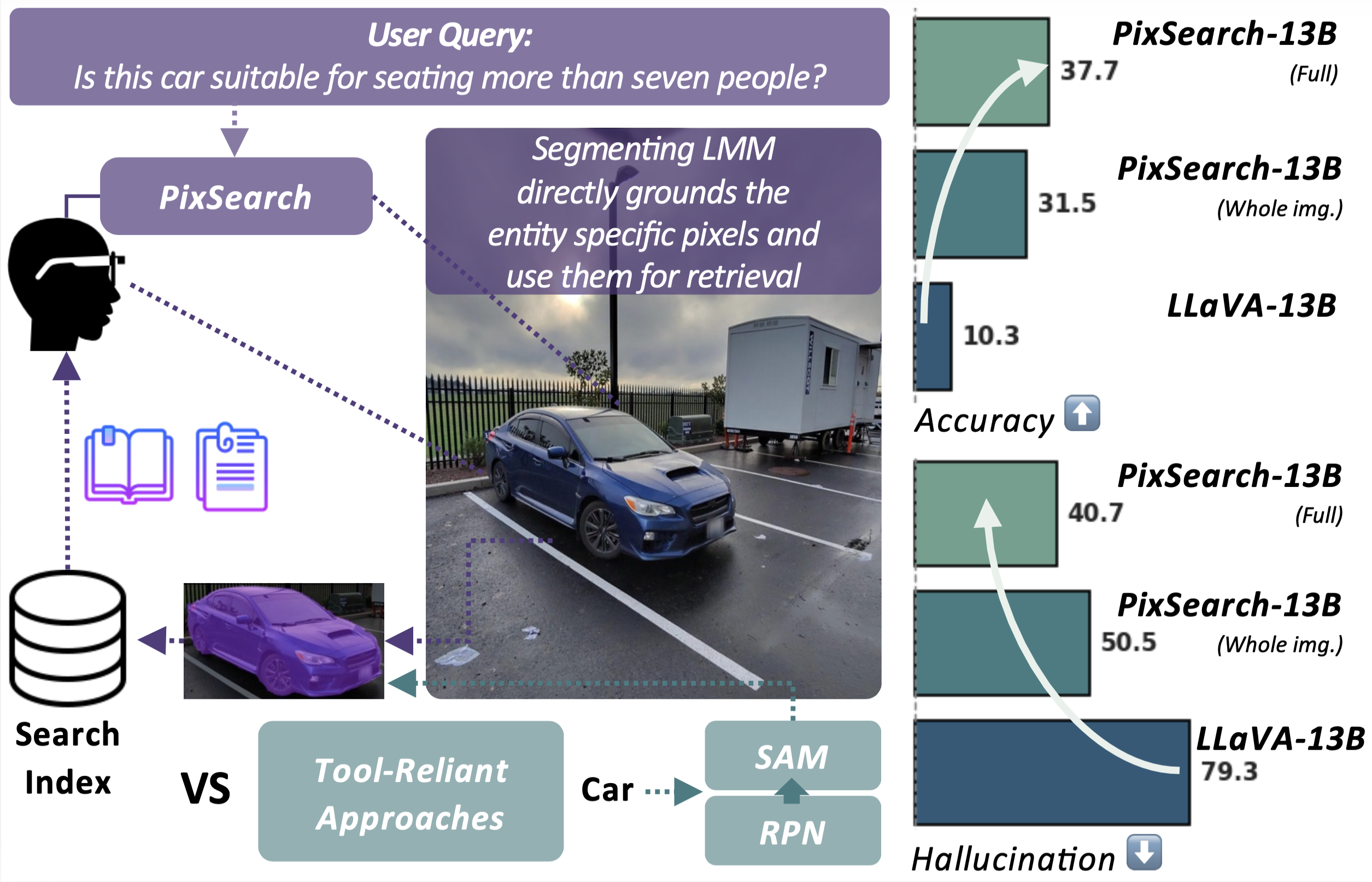
Pixel-Grounded Retrieval for Knowledgeable Large Multimodal Models
Jeonghwan Kim, Renjie Tao, Sanat Sharma, Jiaqi Wang, Kai Sun, Zhaojiang Lin, Seungwhan Moon, Lambert Mathias, Anuj Kumar, Heng Ji, Xin Luna Dong
Preprint, 2026

Alignment-Aware Training for Generalizable VLAs
Dwip Dalal, Shivansh Patel, Jeonghwan Kim, Utkarsh Mishra, Alex Baratian, Hyeonjeong Ha, Heng Ji, Svetlana Lazebnik, Unnat Jain
Preprint, 2026
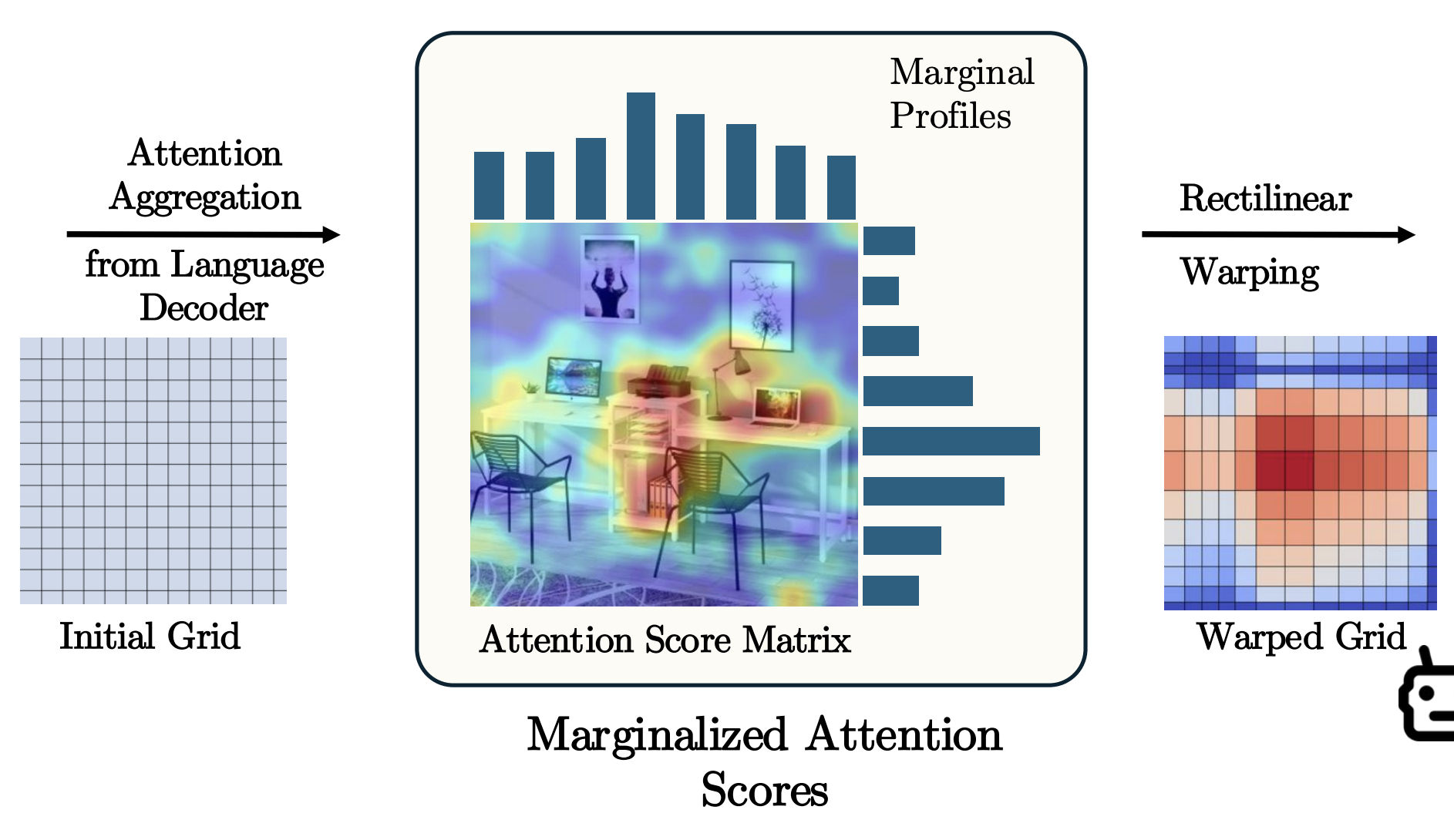
Constructive Distortion: Improving MLLMs with Attention-Guided Image Warping
Dwip Dalal, Gautam Vashishtha, Utkarsh Mishra, Jeonghwan Kim, Madhav Kanda, Hyeonjeong Ha, Svetlana Lazebnik, Heng Ji, Unnat Jain
ICLR 2026
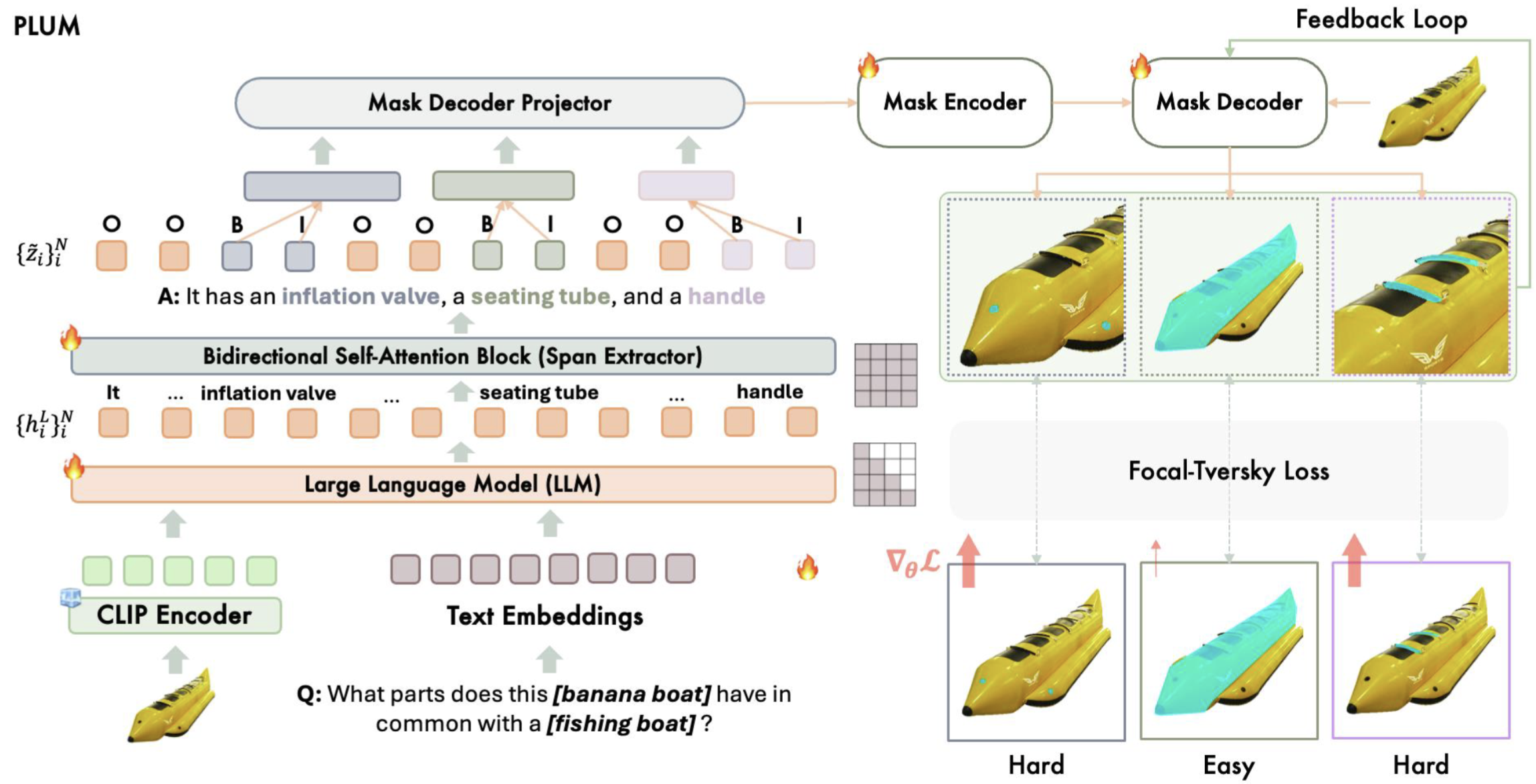
PARTONOMY: Large Multimodal Models with Part-Level Visual Understanding
Ansel Blume*, Jeonghwan Kim*, Hyeonjeong Ha, Elen Chatikyan, Xiaomeng Jin, Khanh Duy Nguyen, Nanyun Peng, Kai-Wei Chang, Derek Hoiem and Heng Ji
NeurIPS 2025 (Spotlight)
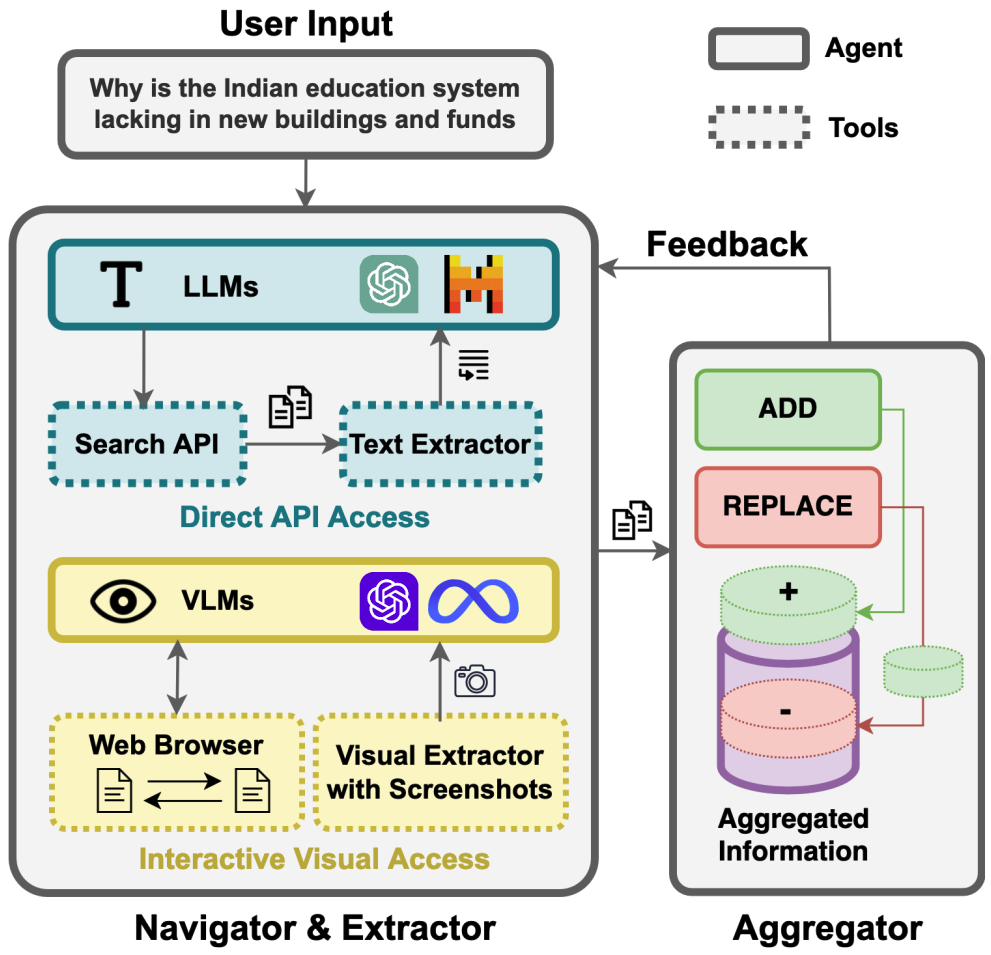
Infogent: An Agent-Based Framework for Web Information Aggregation
Revanth Gangi Reddy*, Sagnik Mukherjee*, Jeonghwan Kim*, Zhenhailong Wang*, Dilek Hakkani-Tur, Heng Ji
NAACL 2025, Findings
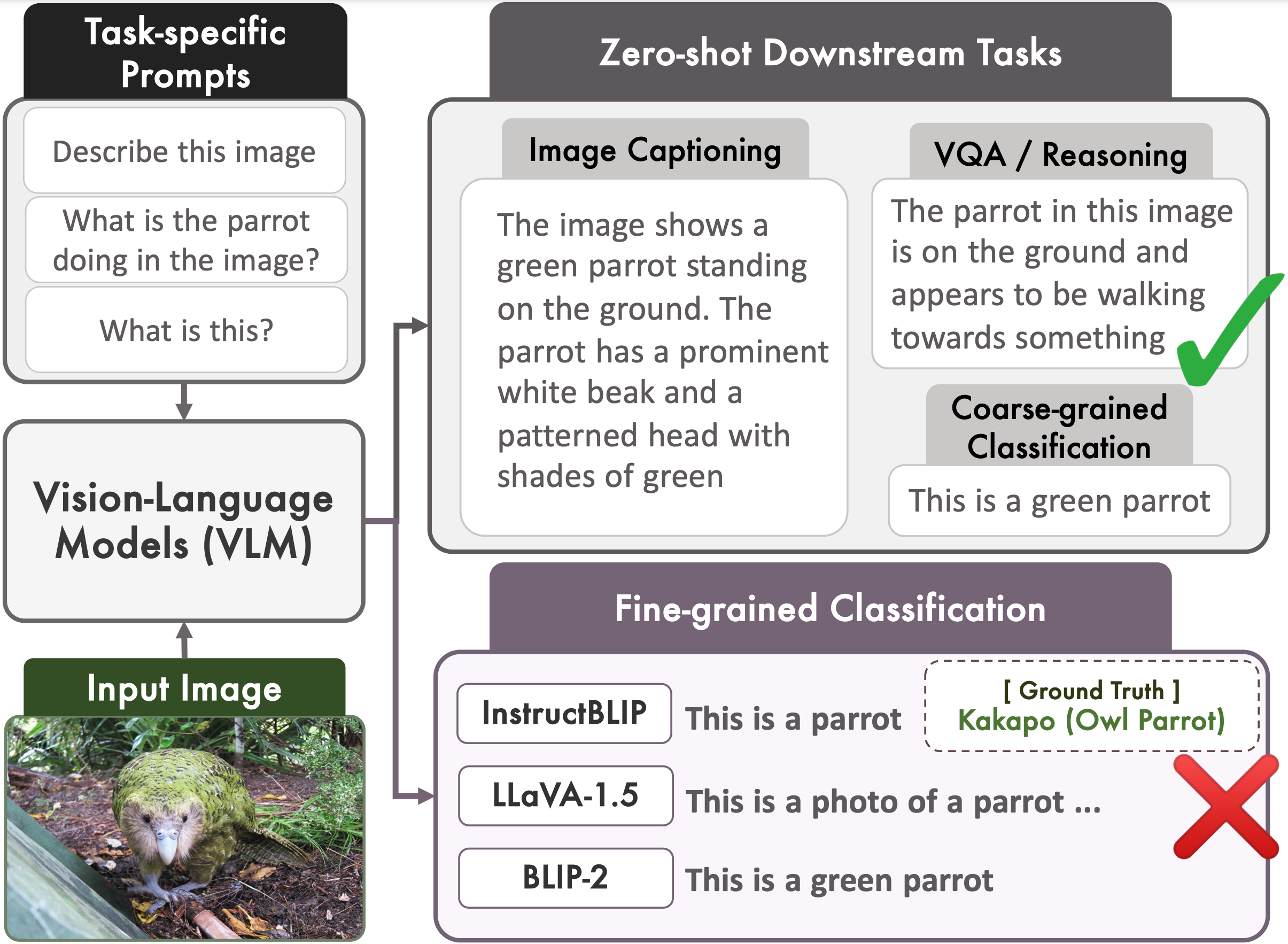
Finer: Investigating and Enhancing Fine-Grained Visual Concept Recognition in Large Vision Language Models
Jeonghwan Kim, Heng Ji
EMNLP 2024
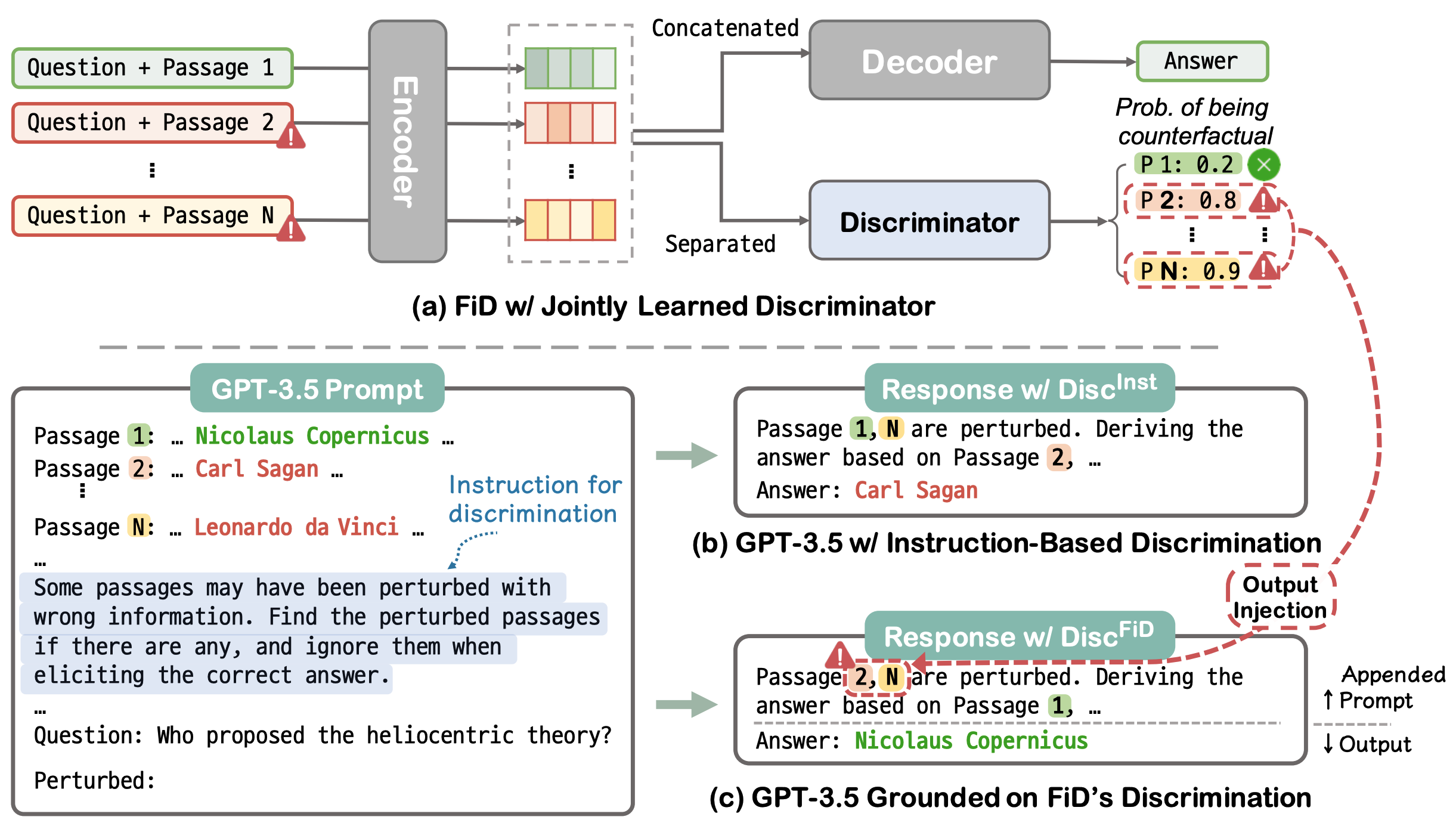
Why So Gullible? Enhancing the Robustness of Retrieval-Augmented Models against Counterfactual Noise
Giwon Hong*, Jeonghwan Kim*, Junmo Kang*, Sung-Hyon Myaeng, Joyce Jiyoung Whang
NAACL 2024, Findings
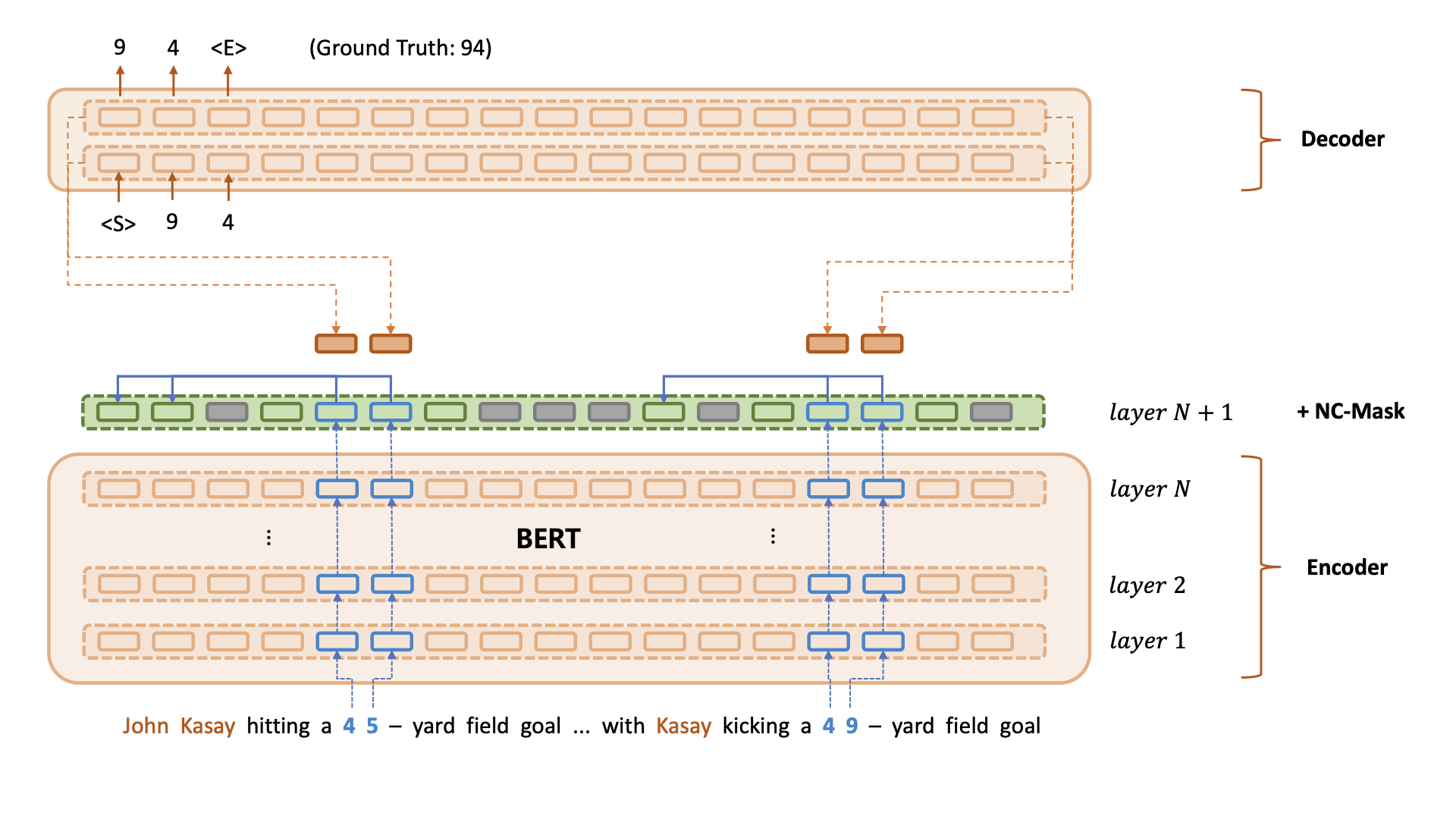
Exploiting Numerical-Contextual Knowledge to Improve Numerical Reasoning in Question Answering
Jeonghwan Kim, Junmo Kang, Giwon Hong, Kyung-min Kim, Sung-Hyon Myaeng
NAACL 2022, Findings
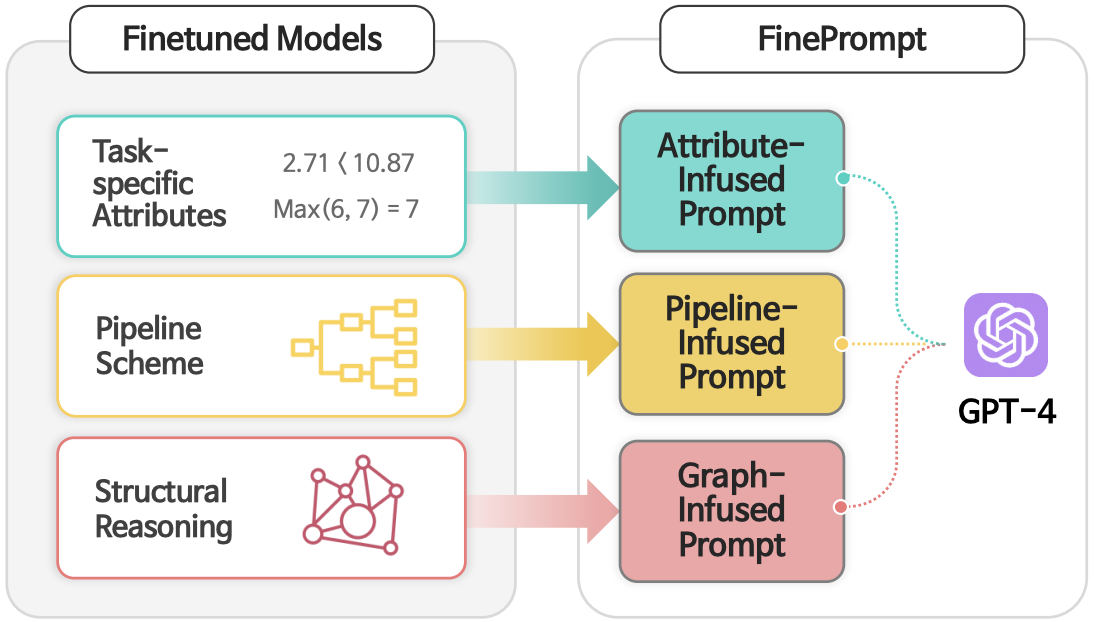
FinePrompt: Unveiling the Role of Finetuned Inductive Bias on Compositional Reasoning in GPT-4
Jeonghwan Kim*, Giwon Hong*, Sung-Hyon Myaeng, Joyce Jiyoung Whang
EMNLP 2023, Findings
Graph-Induced Transformers for Efficient Multi-Hop Question Answering
Giwon Hong, Jeonghwan Kim, Junmo Kang, Sung-Hyon Myaeng
EMNLP 2022

Have You Seen That Number? Investigating Extrapolation in Question Answering Models
Jeonghwan Kim, Giwon Hong, Kyung-min Kim, Junmo Kang, Sung-Hyon Myaeng
EMNLP 2021
Vitæ
Full CV in PDF.
-
Meta May 2026 - PresentResearch Scientist (intern)
World-Action Models for Wearables -
Meta May 2025 - Oct 2025Research Scientist (intern)
Multimodal RAG + MLLM -
Amazon May 2024 - Aug. 2024Applied Scientist (intern)
Multimodal Representation Learning -
UIUC Aug. 2023 - PresentPh.D. in Computer Science
BLENDER Lab -
IR&NLP Lab, KAIST Mar. 2022 - Jul. 2023Researcher
Working on QA and Graph Networks -
KAIST Feb. 2020 - Feb. 2022M.Sc. in School of Computing
IR&NLP Lab -
Republic of Korea Marine Corps Mar. 2015 - Dec. 2016Honorably Discharged
Mandatory Military Service -
Handong Global University Mar. 2014 - Feb. 2020B.Sc. in Computer Science & Electrical Engineering
Magna Cum Laude